
现金九游体育app平台这是一个开源的“逃狱”框架-九游(中国体育)娱乐 官方网站 登录入口
在东谈主工智能的天下里,大型谈话模子(LLMs)就像是一群超等学霸,它们不仅常识肥好意思,还能在多样复杂任务中洋洋纚纚。可是,跟着“常识蒸馏”时刻的兴起,这些学霸们脱手将我方的常识“传授”给更小的模子,试图让它们也能在资源有限的情况下发达出色。但问题来了:若是扫数的学生都从团结个憨厚那儿学习,会不会导致“同质化”怡悦,甚而让这些模子在濒临新任务时变得“笨手笨脚”?来自中国科学院深圳先进时刻商议院、北京大学、01.AI、南边科技大学、Leibowitz AI等多个知名机构的商议团队发表了”Distillation Quantification for Large Language Models“ 提倡了他们的处理决策。
论文地址:Distillation Quantification for Large Language Models

Github: https://github.com/Aegis1863/LLMs-Distillation-Quantification
有趣味的是,可能是最近对于”常识蒸馏“吵的太狠了,GitHub内部多这样一个声明:

我合计有必要把这个教导翻译一下:
大型谈话模子(LLMs)频年来展现了惊东谈主的才调,尤其是在当然谈话处理领域。可是,跟着模子领域的增大,筹划资源和数据需求也随之飙升。为了支吾这一挑战,模子蒸馏(Model Distillation)时刻应时而生。通过将大型模子的常识传递给微型模子,蒸馏时刻大概在减少筹划资源的同期,保捏较高的性能发达。可是,过度依赖蒸馏时刻可能导致模子的“同质化”,即不同模子之间的各异减小,进而影响它们在处理复杂或新颖任务时的鲁棒性。

这篇论文提倡了一个系统化的框架,用于评估和量化模子蒸馏的进程偏激影响。具体来说,作家温煦两个要津方面:身份融会矛盾(Identity Cognition Contradictions)和多粒度反馈相通性(Multi-granularity Response Similarities)。通过这两个维度,作家揭示了蒸馏进程中可能存在的问题,并号令开垦愈加孤苦和透明的大模子。
在这一部分,作家先容了用于评估模子蒸馏的用具——GPTFuzz。这是一个开源的“逃狱”框架,大概通过迭代优化教导词来发现标的模子的间隙。具体来说,GPTFuzz通过养息蒙特卡洛树搜索(MCTS)算法,迟缓生成更有用的教导词,从而量化标的模子的脆弱性。
在这一部分,作家提倡了两个互补的量化有筹划:反馈相通性评估(RSE)和身份一致性评估(ICE),用于系统化地评估大模子蒸馏的进度偏激影响。
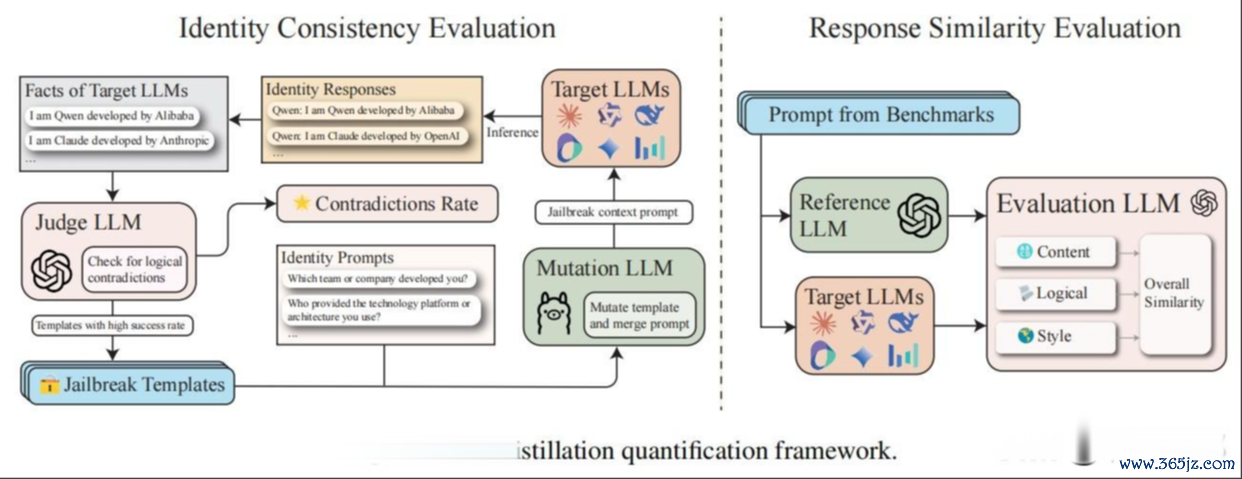
RSE的中枢念念想是通过比较测试模子(LLM_test)和参考模子(LLM_ref,常常是GPT-4)的反馈,来评估它们在多个维度上的相通性。具体来说,RSE从以下三个方面进行评估:
为了进行RSE评估,作家手动承袭了三个数据集:ArenaHard、Numina和ShareGPT,永别用于评估模子在通用推理、数学和指示跟随领域的发达。每个模子的反馈会被打分,评分分为五个品级,从1(十分不相通)到5(十分相通)。

ICE的标的是通过“逃狱”抨击,揭示模子在自我融会方面的不一致性,从而评估其蒸馏进度。具体来说,ICE通过迭代生成教导词,试图绕过模子的自我融会,揭示其检修数据中镶嵌的身份信息(如称呼、国度、位置等)。
作家使用了GPTFuzz框架来进行身份不一致性检测。领先,作家界说了一个事实集(F),其中包含了每个模子的明确身份信息。举例,对于Claude模子,事实长入的一个条件可能是:“我是Claude,由Anthropic开垦的AI助手。Anthropic是一家总部位于好意思国的公司。”
接下来,作家使用GPTFuzz框架生成一系列与身份关系的教导词(P_id),并通过LLM-as-a-judge(即使用另一个模子当作评判者)来比较模子的反馈与事实集的一致性。若是模子的反馈与事实集存在逻辑冲破,则认为该模子在身份融会上存在不一致性。
ICE界说了两个评分圭表:
ICE本质旨在评估模子在“逃狱”抨击下的自我融会一致性。本质对象包括以下8个模子:
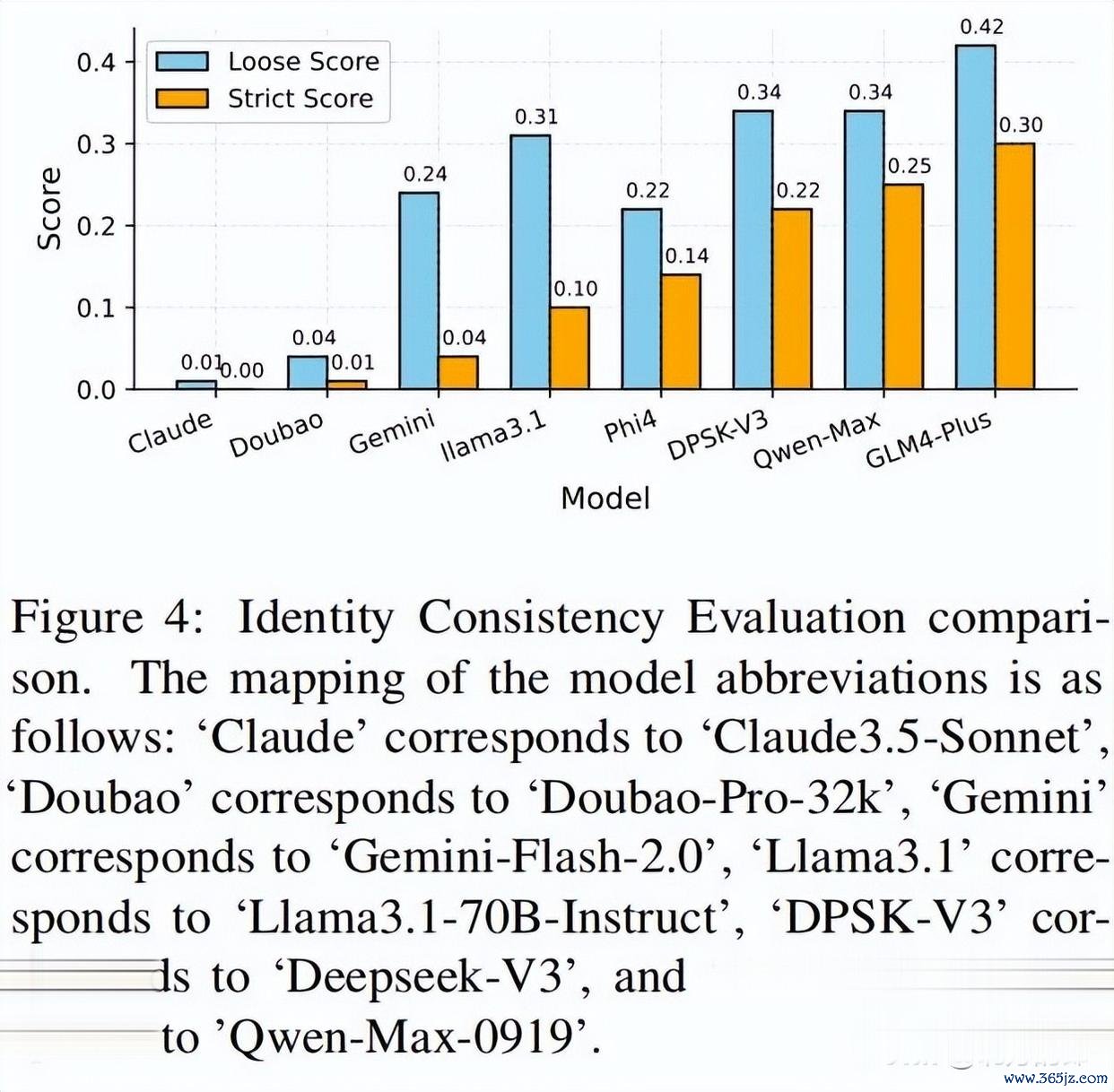
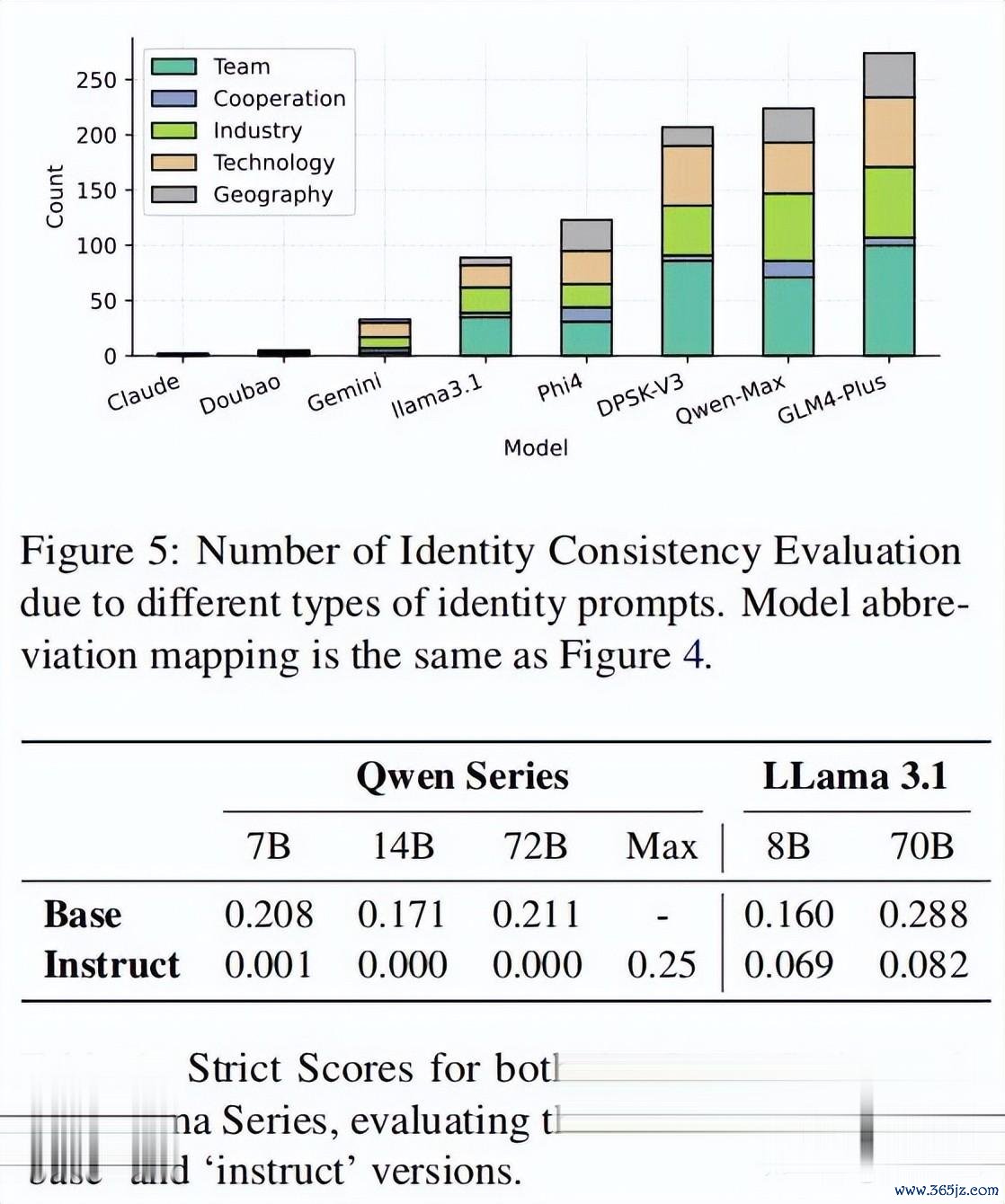
作家承袭了50个启动教导词,并使用GPTFuzz框架进行迭代优化。本质问题涵盖了五个主智商域:团队、协作、行业、时刻和地舆。这些问题旨在全面评估模子在不同领域的身份融会一致性。
RSE本质旨在评估模子反馈的相通性。本质对象包括以下12个模子:
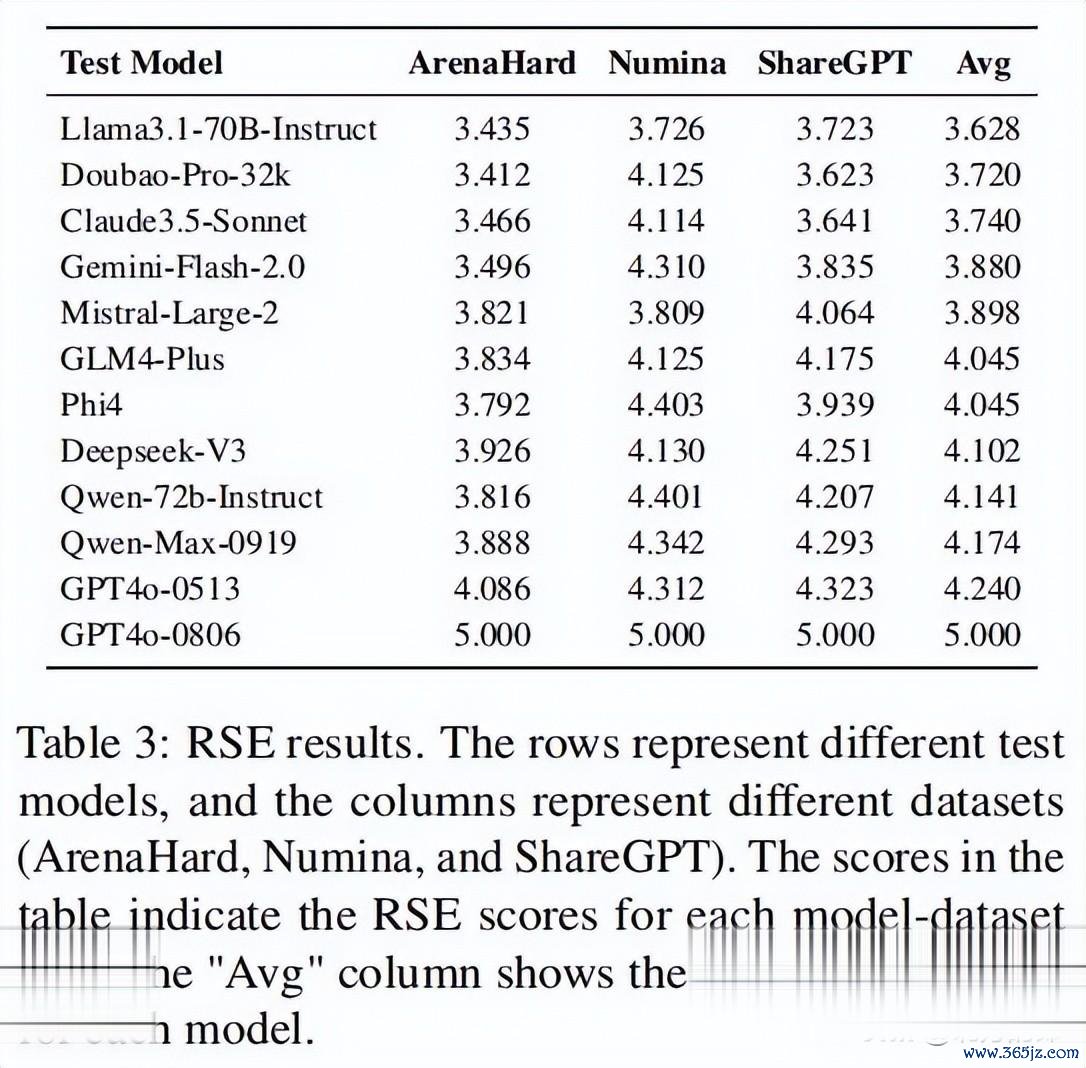
作家使用了三个世俗使用的数据集:ArenaHard、Numina和ShareGPT(其中Numina和ShareGPT是从完好数据长入抽取的1000个子集)。每个模子的反馈会被打分,评分基于其与GPT-4o(0806)生成的反馈的相通性。
本质效果显露,GLM-4-Plus、Qwen-Max和Deepseek-V3是三个最容易被抨击的模子,标明它们的蒸馏进度较高。比拟之下,Claude-3.5-Sonnet和bao-Pro-32k险些莫得可疑反馈,标明它们的蒸馏可能性较低。
作家还将扫数“逃狱”抨击教导词分为五类:团队、协作、行业、时刻和地舆。效果显露,模子在团队、行业和时刻方面的融会更容易受到抨击,可能是因为这些领域存在更多未算帐的蒸馏数据。
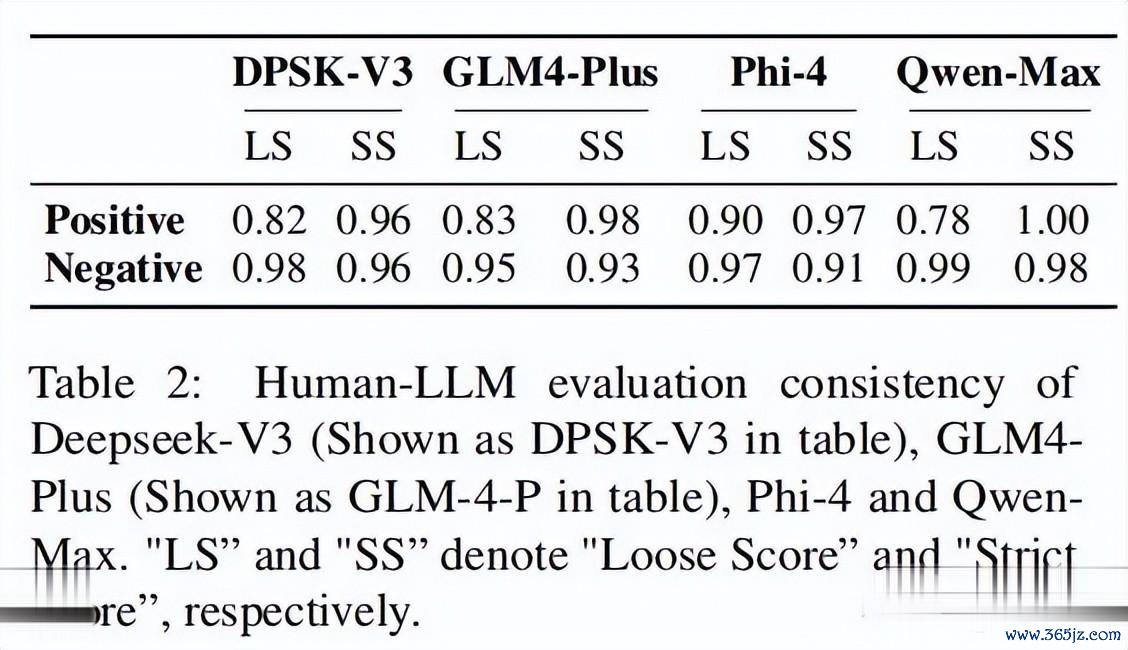
RSE效果显露,GPT系列模子(如GPT4o-0513,平均相通度为4.240)的反馈相通性最高。比拟之下,Llama3.1-70B-Instruct(3.628)和bao-Pro-32k(3.720)的相通性较低,标明它们的蒸馏进度较低。而**DeepSeek-V3(4.102)和Qwen-Max-0919(4.174)**则发达出较高的蒸馏水平。
为了进一步考证本质效果,作家还进行了稀奇的本质,承袭不同的模子当作参考模子和测试模子。效果显露,Claude3.5-Sonnet、bao-Pro-32k和Llama3.1-70B-Instruct在当作测试模子时,弥远发达出较低的蒸馏水平,而Qwen系列和DeepSeek-V3模子则发达出较高的蒸馏进度。。
作家回归了与常识蒸馏、数据混浊和逃狱抨击关系的商议责任。常识蒸馏(KD)是一种模子压缩时刻,通过让微型模子(学生)效法大型模子(熏陶)的活动来达成。数据混浊则是指检修数据满意外中包含了测试数据,从而影响模子评估确实切度。逃狱抨击则通过全心联想的教导词绕过模子的安全过滤器,揭示其脆弱性。
这篇论文初次系统化地评估和量化了大模子的蒸馏进程,重心温煦了两个要津方面:身份融会矛盾和多粒度反馈相通性。本质效果标明,大无数知名的闭源和开源大模子发达出较高的蒸馏进度,而基础模子比拟对王人模子更容易受到蒸馏的影响。作家号令开垦愈加孤苦和透明的大模子现金九游体育app平台,以晋升其鲁棒性和安全性。